
Latest recommendations

| Id | Title * ▲ | Authors * | Abstract * | Picture * | Thematic fields * | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
23 Jul 2024
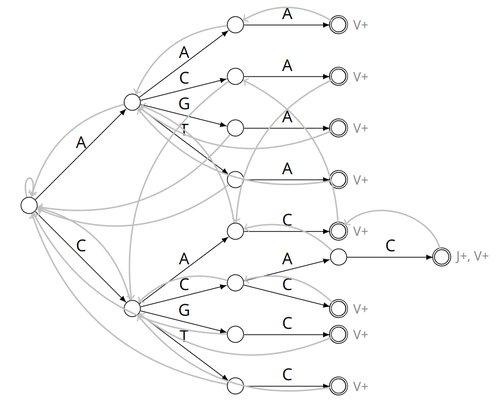
Alignment-free detection and seed-based identification of multi-loci V(D)J recombinations in Vidjil-algoAn accelerated Vidjil algorithm: up to 30X faster identification of V(D)J recombinations via spaced seeds and Aho-Corasick pattern matchingRecommended by Giulio Ermanno Pibiri based on reviews by Sven Rahmann and 1 anonymous reviewer based on reviews by Sven Rahmann and 1 anonymous reviewer
VDJ recombination is a crucial process in the immune system, where a V (variable) gene, a D (diversity) gene, and a J (joining) gene are randomly combined to create unique antigen receptor genes. This process generates a vast diversity of antibodies and T-cell receptors, essential for recognizing and combating a wide array of pathogens. By identifying and quantifying these VDJ recombinations, we can gain a deeper and more precise understanding of the immune response, enhancing our ability to monitor and manage immune-related conditions. It is therefore important to develop efficient methods to identify and extract VDJ recombinations from large sequences (e.g., several millions/billions of nucleotides). The work by Borée, Giraud, and Salson [2] contributes one such algorithm. As in previous work, the proposed algorithm employs the Aho-Corasick automaton to simultaneously match several patterns against a string but, differently from other methods, it also combines the efficiency of spaced seeds. Working with seeds rather than the original string has the net benefit of speeding up the algorithm and reducing its memory usage, sometimes at the price of a modest loss in accuracy. Experiments conducted on five different datasets demonstrate that these features grant the proposed method excellent practical performance compared to the best previous methods, like Vidjil [3] (up to 5X faster) and MiXCR [1] (up to 30X faster), with no quality loss. The method can also be considered an excellent example of a more general trend in scalable algorithmic design: adapt "classic" algorithms (in this case, the Aho-Corasick pattern matching algorithm) to work in sketch space (e.g., the spaced seeds used here), trading accuracy for efficiency. Sometimes, this compromise is necessary for the sake of scaling to very large datasets using modest computing power. References [1] D. A. Bolotin, S. Poslavsky, I. Mitrophanov, M. Shugay, I. Z. Mamedov, E. V. Putintseva, and D. M. Chudakov (2015). "MiXCR: software for comprehensive adaptive immunity profiling." Nature Methods 12, 380–381. ISSN: 1548-7091. https://doi.org/10.1038/nmeth.3364 [2] C. Borée, M. Giraud, M. Salson (2024) "Alignment-free detection and seed-based identification of multi-loci V(D)J recombinations in Vidjil-algo". https://hal.science/hal-04361907v2, version 2, peer-reviewed and recommended by Peer Community In Mathematical and Computational Biology. [3] M. Giraud, M. Salson, M. Duez, C. Villenet, S. Quief, A. Caillault, N. Grardel, C. Roumier, C. Preudhomme, and M. Figeac (2014). "Fast multiclonal clusterization of V(D)J recombinations from high-throughput sequencing". BMC Genomics 15, 409. https://doi.org/10.1186/1471-2164-15-409. | Alignment-free detection and seed-based identification of multi-loci V(D)J recombinations in Vidjil-algo | Cyprien Borée, Mathieu Giraud, Mikaël Salson | <p>The diversity of the immune repertoire is grounded on V(D)J recombinations in several loci. Many algorithms and software detect and designate these recombinations in high-throughput sequencing data. To improve their efficiency, we propose a mul... | | Combinatorics, Computational complexity, Design and analysis of algorithms, Genomics and Transcriptomics, Immunology | Giulio Ermanno Pibiri | 2023-12-28 18:03:42 | ||
24 Dec 2020
A linear time solution to the Labeled Robinson-Foulds Distance problemComparing reconciled gene trees in linear timeRecommended by Céline Scornavacca based on reviews by Barbara Holland, Gabriel Cardona, Jean-Baka Domelevo Entfellner and 1 anonymous reviewer
Unlike a species tree, a gene tree results not only from speciation events, but also from events acting at the gene level, such as duplications and losses of gene copies, and gene transfer events [1]. The reconciliation of phylogenetic trees consists in embedding a given gene tree into a known species tree and, doing so, determining the location of these gene-level events on the gene tree [2]. Reconciled gene trees can be seen as phylogenetic trees where internal node labels are used to discriminate between different gene-level events. Comparing them is of foremost importance in order to assess the performance of various reconciliation methods (e.g. [3]). References [1] Maddison, W. P. (1997). Gene trees in species trees. Systematic biology, 46(3), 523-536. doi: https://doi.org/10.1093/sysbio/46.3.523 | A linear time solution to the Labeled Robinson-Foulds Distance problem | Samuel Briand, Christophe Dessimoz, Nadia El-Mabrouk and Yannis Nevers | <p>Motivation Comparing trees is a basic task for many purposes, and especially in phylogeny where different tree reconstruction tools may lead to different trees, likely representing contradictory evolutionary information. While a large variety o... | | Combinatorics, Design and analysis of algorithms, Evolutionary Biology | Céline Scornavacca | 2020-08-20 21:06:23 | ||
09 Nov 2023
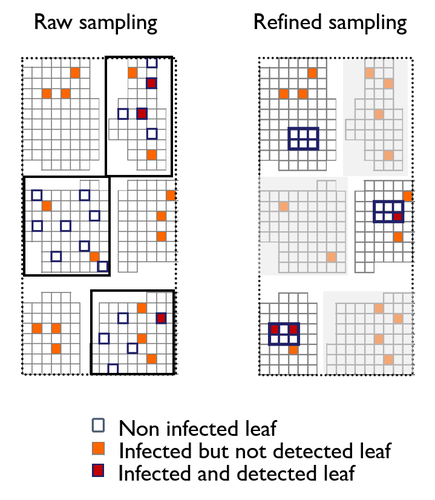
A mechanistic-statistical approach to infer dispersal and demography from invasion dynamics, applied to a plant pathogenA mechanistic-statistical approach for the field-based study of invasion dynamicsRecommended by Hirohisa Kishino based on reviews by 2 anonymous reviewers
To study the annual invasion of a tree pathogen (Melampsora larici-populina, a fungal species responsible for the poplar rust disease), Xhaard et al (2012) had conducted a spatiotemporal survey along the Durance River valley in the French Alps over nearly 200 km, measuring sampled leaves and twigs from 40 to 150 trees at 12 evenly spaced study sites at seven-time points. By combining Bayesian genetic assignment and a landscape epidemiology approach, they were able to estimate the genetic origin and annual spread of the plant pathogen during a single epidemic. The observed temporal variation in the spatial pattern of infection rates allowed Saubin et al (2023) to estimate the key factors that determine the speed of the invasion dynamics. In particular, it is crucial to estimate the probability and extent of long-distance dispersal. The dynamics of the macroscale population density was formulated by the reaction-diffusion (R.D.) model and by the integro-difference (I.D.) model. Both consist of the diffusion/dispersal component and the reaction component. In the I.D. model, the kernel function represents the distribution of the dispersion. The likelihood function was obtained by coupling the mathematical model of the population dynamics and the statistical model of the observational process. Saubin et al (2023) considered a thin-tailed Gaussian kernel, a heavy-tailed exponential kernel, and a fat-tailed exponential power kernel. The numerical simulation reflecting the above survey confirmed the identifiability of the propagation kernel and the accuracy of the parameter estimation. In particular, the above survey had the high power to identify the model with frequent long-distance dispersal. The data from the survey selected the exponential power kernel with confidence. The mean dispersal distance was estimated to be 2.01 km. The exponential power was 0.24. This parameter value predicts that 5% of the dispersals will have a distance > 14.3 km and 1% will have a distance > 36.0 km. The mechanistic-statistical approach presented here may become a new standard for the field-based studies of invasion dynamics. References Saubin, M., Coville, J., Xhaard, C., Frey, P., Soubeyrand, S., Halkett, F., and Fabre, F. (2023). A mechanistic-statistical approach to infer dispersal and demography from invasion dynamics, applied to a plant pathogen. bioRxiv, ver. 5 peer-reviewed and recommended by Peer Community in Mathematical and Computational Biology. https://doi.org/10.1101/2023.03.21.533642 Xhaard, C., Barrès, B., Andrieux, A., Bousset, L., Halkett, F., and Frey, P. (2012). Disentangling the genetic origins of a plant pathogen during disease spread using an original molecular epidemiology approach. Molecular Ecology, 21(10):2383-2398. https://doi.org/10.1111/j.1365-294X.2012.05556.x | A mechanistic-statistical approach to infer dispersal and demography from invasion dynamics, applied to a plant pathogen | Méline Saubin, Jérome Coville, Constance Xhaard, Pascal Frey, Samuel Soubeyrand, Fabien Halkett, Frédéric Fabre | <p style="text-align: justify;">Dispersal, and in particular the frequency of long-distance dispersal (LDD) events, has strong implications for population dynamics with possibly the acceleration of the colonisation front, and for evolution with po... | | Dynamical systems, Ecology, Epidemiology, Probability and statistics | Hirohisa Kishino | 2023-05-10 09:57:25 | ||
10 Jan 2024
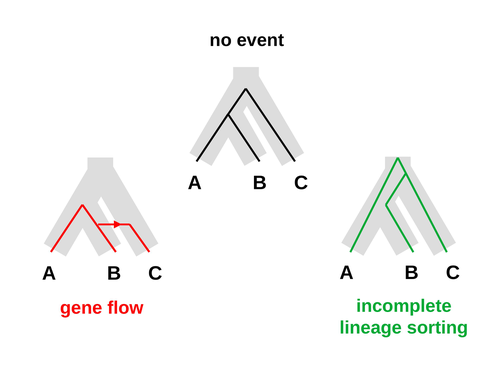
An approximate likelihood method reveals ancient gene flow between human, chimpanzee and gorillaAphid: A Novel Statistical Method for Dissecting Gene Flow and Lineage Sorting in Phylogenetic ConflictRecommended by Alan Rogers based on reviews by Richard Durbin and 2 anonymous reviewers
Galtier [1] introduces “Aphid,” a new statistical method that estimates the contributions of gene flow (GF) and incomplete lineage sorting (ILS) to phylogenetic conflict. Aphid is based on the observation that GF tends to make gene genealogies shorter, whereas ILS makes them longer. Rather than fitting the full likelihood, it models the distribution of gene genealogies as a mixture of several canonical gene genealogies in which coalescence times are set equal to their expectations under different models. This simplification makes Aphid far faster than competing methods. In addition, it deals gracefully with bidirectional gene flow—an impossibility under competing models. Because of these advantages, Aphid represents an important addition to the toolkit of evolutionary genetics. In the interest of speed, Aphid makes several simplifying assumptions. Yet even when these were violated, Aphid did well at estimating parameters from simulated data. It seems to be reasonably robust. Aphid studies phylogenetic conflict, which occurs when some loci imply one phylogenetic tree and other loci imply another. This happens when the interval between successive speciation events is fairly short. If this interval is too short, however, Aphid’s approximations break down, and its estimates are biased. Galtier suggests caution when the fraction of discordant phylogenetic trees exceeds 50–55%. Thus, Aphids will be most useful when the interval between speciation events is short, but not too short. Galtier applies the new method to three sets of primate data. In two of these data sets (baboons and African apes), Aphid detects gene flow that would likely be missed by competing methods. These competing methods are primarily sensitive to gene flow that is asymmetric in two senses: (1) greater flow in one direction than the other, and (2) unequal gene flow connecting an outgroup to two sister species. Aphid finds evidence of symmetric gene flow in the ancestry of baboons and also in that of African apes. The data suggest that ancestral humans and chimpanzees both interbred with ancestral gorillas, and at about the same rate. Aphid’s ability to detect this signature sets it apart from competing methods. References [1] Nicolas Galtier (2023) “An approximate likelihood method reveals ancient gene flow between human, chimpanzee and gorilla”. bioRxiv, ver. 3 peer-reviewed and recommended by Peer Community in Mathematical and Computational Biology. https://doi.org/10.1101/2023.07.06.547897 | An approximate likelihood method reveals ancient gene flow between human, chimpanzee and gorilla | Nicolas Galtier | <p>Gene flow and incomplete lineage sorting are two distinct sources of phylogenetic conflict, i.e., gene trees that differ in topology from each other and from the species tree. Distinguishing between the two processes is a key objective of curre... | | Evolutionary Biology, Genetics and population Genetics, Genomics and Transcriptomics | Alan Rogers | 2023-07-06 18:41:16 | ||
26 May 2021
An efficient algorithm for estimating population history from genetic dataAn efficient implementation of legofit software to infer demographic histories from population genetic dataRecommended by Matteo Fumagalli based on reviews by Fernando Racimo and 1 anonymous reviewer
The estimation of demographic parameters from population genetic data has been the subject of many scientific studies [1]. Among these efforts, legofit was firstly proposed in 2019 as a tool to infer size changes, subdivision and gene flow events from patterns of nucleotidic variation [2]. The first release of legofit used a stochastic algorithm to fit population parameters to the observed data. As it requires simulations to evaluate the fitting of each model, it is computationally intensive and can only be deployed on high-performance computing clusters. To overcome this issue, Rogers proposes a new implementation of legofit based on a deterministic algorithm that allows the estimation of demographic histories to be computationally faster and more accurate [3]. The new algorithm employs a continuous-time Markov chain that traces the ancestry of each sample into the past. The calculations are now divided into two steps, the first one being solved numerically. To test the hypothesis that the new implementation of legofit produces a more desirable performance, Rogers generated extensive simulations of genomes from African, European, Neanderthal and Denisovan populations with msprime [4]. Additionally, legofit was tested on real genetic data from samples of said populations, following a previously published study [5]. Based on simulations, the new deterministic algorithm is more than 1600 times faster than the previous stochastic model. Notably, the new version of legofit produces smaller residual errors, although the overall accuracy to estimate population parameters is comparable to the one obtained using the stochastic algorithm. When applied to real data, the new implementation of legofit was able to recapitulate previous findings of a complex demographic model with early gene flow from humans to Neanderthal [5]. Notably, the new implementation generates better discrimination between models, therefore leading to a better precision at predicting the population history. Some parameters estimated from real data point towards unrealistic scenarios, suggesting that the initial model could be misspecified. Further research is needed to fully explore the parameter range that can be evaluated by legofit, and to clarify the source of any associated bias. Additionally, the inclusion of data uncertainty in parameter estimation and model selection may be required to apply legofit to low-coverage high-throughput sequencing data [6]. Nevertheless, legofit is an efficient, accessible and user-friendly software to infer demographic parameters from genetic data and can be widely applied to test hypotheses in evolutionary biology. The new implementation of legofit software is freely available at https://github.com/alanrogers/legofit. References [1] Spence JP, Steinrücken M, Terhorst J, Song YS (2018) Inference of population history using coalescent HMMs: review and outlook. Current Opinion in Genetics & Development, 53, 70–76. https://doi.org/10.1016/j.gde.2018.07.002 [2] Rogers AR (2019) Legofit: estimating population history from genetic data. BMC Bioinformatics, 20, 526. https://doi.org/10.1186/s12859-019-3154-1 [3] Rogers AR (2021) An Efficient Algorithm for Estimating Population History from Genetic Data. bioRxiv, 2021.01.23.427922, ver. 5 peer-reviewed and recommended by Peer community in Mathematical and Computational Biology. https://doi.org/10.1101/2021.01.23.427922 [4] Kelleher J, Etheridge AM, McVean G (2016) Efficient Coalescent Simulation and Genealogical Analysis for Large Sample Sizes. PLOS Computational Biology, 12, e1004842. https://doi.org/10.1371/journal.pcbi.1004842 [5] Rogers AR, Harris NS, Achenbach AA (2020) Neanderthal-Denisovan ancestors interbred with a distantly related hominin. Science Advances, 6, eaay5483. https://doi.org/10.1126/sciadv.aay5483 [6] Soraggi S, Wiuf C, Albrechtsen A (2018) Powerful Inference with the D-Statistic on Low-Coverage Whole-Genome Data. G3 Genes|Genomes|Genetics, 8, 551–566. https://doi.org/10.1534/g3.117.300192 | An efficient algorithm for estimating population history from genetic data | Alan R. Rogers | <p style="text-align: justify;">The Legofit statistical package uses genetic data to estimate parameters describing population history. Previous versions used computer simulations to estimate probabilities, an approach that limited both speed and ... | | Combinatorics, Genetics and population Genetics | Matteo Fumagalli | 2021-01-26 20:04:35 | ||
26 Feb 2024

A workflow for processing global datasets: application to intercroppingCollecting, assembling and sharing data in crop sciencesRecommended by Eric Tannier based on reviews by Christine Dillmann and 2 anonymous reviewers
It is often the case that scientific knowledge exists but is scattered across numerous experimental studies. Because of this dispersion in different formats, it remains difficult to access, extract, reproduce, confirm or generalise. This is the case in crop science, where Mahmoud et al [1] propose to collect and assemble data from numerous field experiments on intercropping. It happens that the construction of the global dataset requires a lot of time, attention and a well thought-out method, inspired by the literature on data science [2] and adapted to the specificities of crop science. This activity also leads to new possibilities that were not available in individual datasets, such as the detection of full factorial designs using graph theory tools developed on top of the global dataset. The study by Mahmoud et al [1] has thus multiple dimensions:
I was particularly interested in the promotion of the FAIR principles, perhaps used a little too uncritically in my view, as an obvious solution to data sharing. On the one hand, I am admiring and grateful for the availability of these data, some of which have never been published, nor associated with published results. This approach is likely to unearth buried treasures. On the other hand, I can understand the reluctance of some data producers to commit to total, definitive sharing, facilitating automatic reading, without having thought about a certain reciprocity on the part of users and use by artificial intelligence. Reciprocity in terms of recognition, as is discussed by Mahmoud et al [1], but also in terms of contribution to the commons [5] or reading conditions for machine learning. References [1] Mahmoud R., Casadebaig P., Hilgert N., Gaudio N. A workflow for processing global datasets: application to intercropping. 2024. ⟨hal-04145269v2⟩ ver. 2 peer-reviewed and recommended by Peer Community in Mathematical and Computational Biology. https://hal.science/hal-04145269 [2] Wickham, H. 2014. Tidy data. Journal of Statistical Software 59(10) https://doi.org/10.18637/jss.v059.i10 [3] Gaudio, N., R. Mahmoud, L. Bedoussac, E. Justes, E.-P. Journet, et al. 2023. A global dataset gathering 37 field experiments involving cereal-legume intercrops and their corresponding sole crops. https://doi.org/10.5281/zenodo.8081577 [4] Mahmoud, R., Casadebaig, P., Hilgert, N. et al. Species choice and N fertilization influence yield gains through complementarity and selection effects in cereal-legume intercrops. Agron. Sustain. Dev. 42, 12 (2022). https://doi.org/10.1007/s13593-022-00754-y [5] Bernault, C. « Licences réciproques » et droit d'auteur : l'économie collaborative au service des biens communs ?. Mélanges en l'honneur de François Collart Dutilleul, Dalloz, pp.91-102, 2017, 978-2-247-17057-9. https://shs.hal.science/halshs-01562241 | A workflow for processing global datasets: application to intercropping | Rémi Mahmoud, Pierre Casadebaig, Nadine Hilgert, Noémie Gaudio | <p>Field experiments are a key source of data and knowledge in agricultural research. An emerging practice is to compile the measurements and results of these experiments (rather than the results of publications, as in meta-analysis) into global d... | | Agricultural Science | Eric Tannier | 2023-06-29 15:38:28 | ||
09 Sep 2020
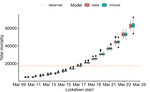
Bayesian investigation of SARS-CoV-2-related mortality in FranceModeling the effect of lockdown and other events on the dynamics of SARS-CoV-2 in FranceRecommended by Valery Forbes based on reviews by Wayne Landis and 1 anonymous reviewerThis study [1] used Bayesian models of the number of deaths through time across different regions of France to explore the effects of lockdown and other events (i.e., holding elections) on the dynamics of the SARS-CoV-2 epidemic. The models accurately predicted the number of deaths 2 to 3 weeks in advance, and results were similar to other recent models using different structure and input data. Viral reproduction numbers were not found to be different between weekends and week days, and there was no evidence that holding elections affected the number of deaths directly. However, exploring different scenarios of the timing of the lockdown showed that this had a substantial impact on the number of deaths. This is an interesting and important paper that can inform adaptive management strategies for controlling the spread of this virus, not just in France, but in other geographic areas. For example, the results found that there was a lag period between a change in management strategies (lockdown, social distancing, and the relaxing of controls) and the observed change in mortality. Also, there was a large variation in the impact of mitigation measures on the viral reproduction number depending on region, with lockdown being slightly more effective in denser regions. The authors provide an extensive amount of additional data and code as supplemental material, which increase the value of this contribution to the rapidly growing literature on SARS-CoV-2. References [1] Duchemin, L., Veber, P. and Boussau, B. (2020) Bayesian investigation of SARS-CoV-2-related mortality in France. medRxiv 2020.06.09.20126862, ver. 5 peer-reviewed and recommended by PCI Mathematical & Computational Biology. doi: 10.1101/2020.06.09.20126862 | Bayesian investigation of SARS-CoV-2-related mortality in France | Louis Duchemin, Philippe Veber, Bastien Boussau | <p>The SARS-CoV-2 epidemic in France has focused a lot of attention as it hashad one of the largest death tolls in Europe. It provides an opportunity to examine the effect of the lockdown and of other events on the dynamics of the epidemic. In par... | | Probability and statistics | Valery Forbes | 2020-07-08 17:29:46 | ||
18 Apr 2023
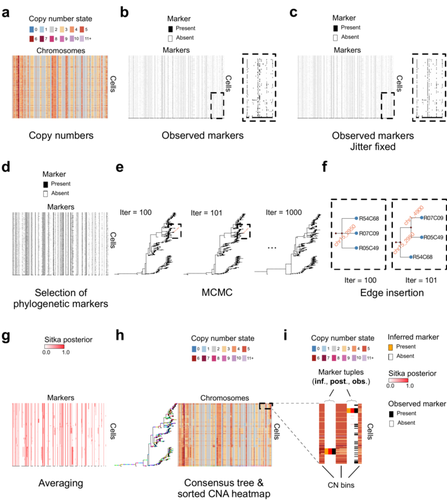
Cancer phylogenetic tree inference at scale from 1000s of single cell genomesPhylogenetic reconstruction from copy number aberration in large scale, low-depth genome-wide single-cell data.Recommended by Amaury Lambert based on reviews by 3 anonymous reviewersThe paper [1] presents and applies a new Bayesian inference method of phylogenetic reconstruction for multiple sequence alignments in the case of low sequencing coverage but diverse copy number aberrations (CNA), with applications to single cell sequencing of tumors. The idea is to take advantage of CNA to reconstruct the topology of the phylogenetic tree of sequenced cells in a first step (the `sitka' method), and in a second step to assign single nucleotide variants (SNV) to tree edges (and then calibrate their lengths) (the `sitka-snv' method). The data are summarized into a binary-valued CxL matrix Y, where C is the number of cells and L is the number of loci (here, loci are segments of prescribed length called `bins'). The entry of Y at row i and column j is 1 (otherwise 0) iff in the ancestral lineage of cell i, at least one genomic rearrangement has occurred, and more specifically the gain or loss of a segment with at least one endpoint in locus j or in locus j+1. The authors expect the infinite-allele assumption to approximately hold (i.e., that at most one mutation occurs at any given marker and that 0 is the ancestral state). They refer to this assumption as the `perfect phylogeny assumption'. By only recording from CNA events the endpoints at which they occur, the authors lose the information on copy number, but they gain the assumption of independence of the mutational processes occurring at different sites, which approximately holds for CNA endpoints. The goal of sitka is to produce a posterior distribution on phylogenetic trees conditional on the matrix Y , where here a phylogenetic tree is understood as containing the information on 1) the topology of the tree but not its edge lengths, and 2) for each edge, the identity of markers having undergone a mutation, in the sense of the previous paragraph. The results of the method are tested against synthetic datasets simulated under various assumptions, including conditions violating the perfect phylogeny assumption and compared to results obtained under other baseline methods. The method is extended to assign SNV to edges of the tree inferred by sitka. It is also applied to real datasets of single cell genomes of tumors. The manuscript is very well-written, with a high degree of detail. The method is novel, scalable, fast and appears to perform favorably compared to other approaches. It has been applied in independent publications, for example to multi-year time-series single-cell whole-genome sequencing of tumors, in order to infer the fitness landscape and its dynamics through time, see [2]. The reviewing process has taken too long, mainly because of other commitments I had during the period and to the difficulty of finding reviewers. Let me apologize to the authors and thank them for their patience as well as for the scientific rigor they brought to their revisions and answers to reviewers, who I also warmly thank for their quality work. REFERENCES [1] Sohrab Salehi, Fatemeh Dorri, Kevin Chern, Farhia Kabeer, Nicole Rusk, Tyler Funnell, Marc J Williams, Daniel Lai, Mirela Andronescu, Kieran R. Campbell, Andrew McPherson, Samuel Aparicio, Andrew Roth, Sohrab Shah, and Alexandre Bouchard-Côté. Cancer phylogenetic tree inference at scale from 1000s of single cell genomes (2023). bioRxiv, 2020.05.06.058180, ver. 4 peer-reviewed and recommended by Peer Community in Mathematical and Computational Biology. [2] Sohrab Salehi, Farhia Kabeer, Nicholas Ceglia, Mirela Andronescu, Marc J. Williams, Kieran R. Campbell, Tehmina Masud, Beixi Wang, Justina Biele, Jazmine Brimhall, David Gee, Hakwoo Lee, Jerome Ting, Allen W. Zhang, Hoa Tran, Ciara O’Flanagan, Fatemeh Dorri, Nicole Rusk, Teresa Ruiz de Algara, So Ra Lee, Brian Yu Chieh Cheng, Peter Eirew, Takako Kono, Jenifer Pham, Diljot Grewal, Daniel Lai, Richard Moore, Andrew J. Mungall, Marco A. Marra, IMAXT Consortium, Andrew McPherson, Alexandre Bouchard-Côté, Samuel Aparicio & Sohrab P. Shah. Clonal fitness inferred from time-series modelling of single-cell cancer genomes (2021). Nature 595, 585–590. https://doi.org/10.1038/s41586-021-03648-3 | Cancer phylogenetic tree inference at scale from 1000s of single cell genomes | Sohrab Salehi, Fatemeh Dorri, Kevin Chern, Farhia Kabeer, Nicole Rusk, Tyler Funnell, Marc J Williams, Daniel Lai, Mirela Andronescu, Kieran R. Campbell, Andrew McPherson, Samuel Aparicio, Andrew Roth, Sohrab Shah, and Alexandre Bouchard-Côté | <p style="text-align: justify;">A new generation of scalable single cell whole genome sequencing (scWGS) methods allows unprecedented high resolution measurement of the evolutionary dynamics of cancer cell populations. Phylogenetic reconstruction ... | | Evolutionary Biology, Genetics and population Genetics, Genomics and Transcriptomics, Machine learning, Probability and statistics | Amaury Lambert | 2021-12-10 17:08:04 | ||
21 Feb 2022
Consistency of orthology and paralogy constraints in the presence of gene transfersAllowing gene transfers doesn't make life easier for inferring orthology and paralogyRecommended by Barbara Holland based on reviews by 2 anonymous reviewersDetermining if genes are orthologous (i.e. homologous genes whose most common ancestor represents a speciation) or paralogous (homologous genes whose most common ancestor represents a duplication) is a foundational problem in bioinformatics. For instance, the input to almost all phylogenetic methods is a sequence alignment of genes assumed to be orthologous. Understanding if genes are paralogs or orthologs can also be important for assigning function, for example genes that have diverged following duplication may be more likely to have neofunctionalised or subfunctionalised compared to genes that have diverged following speciation, which may be more likely to have continued in a similar role. This paper by Jones et al (2022) contributes to a wide range of literature addressing the inference of orthology/paralogy relations but takes a different approach to explaining inconsistency between an assumed species phylogeny and a relation graph (a graph where nodes represent genes and edges represent that the two genes are orthologs). Rather than assuming that inconsistencies are the result of incorrect assessment of orthology (i.e. incorrect edges in the relation graph) they ask if the relation graph could be consistent with a species tree combined with some amount of lateral (horizontal) gene transfer. The two main questions addressed in this paper are (1) if a network N and a relation graph R are consistent, and (2) if – given a species tree S and a relation graph R – transfer arcs can be added to S in such a way that it becomes consistent with R? The first question hinges on the concept of a reconciliation between a gene tree and a network (section 2.1) and amounts to asking if a gene tree can be found that can both be reconciled with the network and consistent with the relation graph. The authors show that the problem is NP hard. Furthermore, the related problem of attempting to find a solution using k or fewer transfers is NP-hard, and also W[1] hard implying that it is in a class of problems for which fixed parameter tractable solutions have not been found. The proof of NP hardness is by reduction to the k-multi-coloured clique problem via an intermediate problem dubbed “antichain on trees” (Section 3). The “antichain on trees” construction may be of interest to others working on algorithmic complexity with phylogenetic networks. In the second question the possible locations of transfers are not specified (or to put it differently any time consistent transfer arc is considered possible) and it is shown that it generally will be possible to add transfer edges to S in such a way that it can be consistent with R. However, the natural extension to this question of asking if it can be done with k or fewer added arcs is also NP hard. Many of the proofs in the paper are quite technical, but the authors have relegated a lot of this detail to the appendix thus ensuring that the main ideas and results are clear to follow in the main text. I am grateful to both reviewers for their detailed reviews and through checking of the proofs. References Jones M, Lafond M, Scornavacca C (2022) Consistency of orthology and paralogy constraints in the presence of gene transfers. arXiv:1705.01240 [cs], ver. 6 peer-reviewed and recommended by Peer Community in Mathematical and Computational Biology. https://arxiv.org/abs/1705.01240 | Consistency of orthology and paralogy constraints in the presence of gene transfers | Mark Jones, Manuel Lafond, Celine Scornavacca | <p style="text-align: justify;">Orthology and paralogy relations are often inferred by methods based on gene sequence similarity that yield a graph depicting the relationships between gene pairs. Such relation graphs frequently contain errors, as ... | | Computational complexity, Design and analysis of algorithms, Evolutionary Biology, Graph theory | Barbara Holland | 2021-06-30 15:01:44 | ||
28 Jun 2024
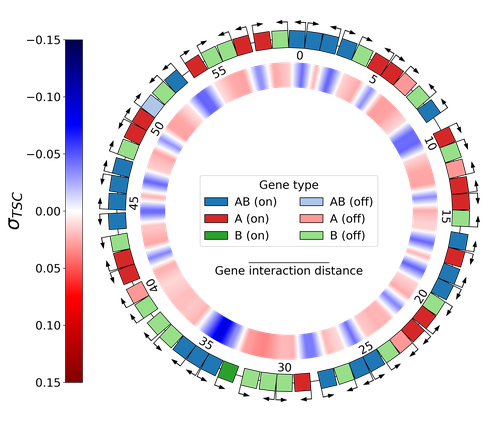
Emergence of Supercoiling-Mediated Regulatory Networks through the Evolution of Bacterial Chromosome OrganizationUnderstanding the impact of the transcription-supercoiling coupling on bacterial genome evolutionRecommended by Nelle Varoquaux based on reviews by Ivan Junier and 1 anonymous reviewer
DNA supercoiling, the under or overwinding of DNA, is known to strongly impact gene expression, as changes in levels of supercoiling directly influence transcription rates. In turn, gene transcription generates DNA supercoiling on each side of an advancing RNA polymerase. This coupling between DNA supercoiling and transcription may result in different outcomes, depending on neighboring gene orientations: divergent genes tend to increase transcription levels, convergent genes tend to inhibit each other, while tandem genes may exhibit more intricate relationships. While several works have investigated the relationship between transcription and supercoiling, Grohens et al [1] address a different question: how does transcription-supercoiling coupling drive genome evolution? To this end, they consider a simple model of gene expression regulation where transcription level only depends on the local DNA supercoiling and where the transcription of one gene generates a linear profile of positive and negative DNA supercoiling on each side of it. They then make genomes evolve through genomic inversions only considering a fitness that reflects the ability of a genome to cope with two distinct environments for which different genes have to be activated or repressed. Using this simple model, the authors illustrate how evolutionary adaptation via genomic inversions can adjust expression levels for enhanced fitness within specific environments, particularly with the emergence of relaxation-activated genes. Investigating the genomic organization of individual genomes revealed that genes are locally organized to leverage the transcription-supercoiling coupling for activation or inhibition, but larger-scale networks of genes are required to strongly inhibit genes (sometimes up to networks of 20 genes). Thus, supercoiling-mediated interactions between genes can implicate more than just local genes. Finally, they construct an "effective interaction graph" between genes by successively simulating gene knock-outs for all of the genes of an individual and observing the effect on the expression level of other genes. They observe a densely connected interaction network, implying that supercoiling-based regulation could evolve concurrently with genome organization in bacterial genomes. References [1] Théotime Grohens, Sam Meyer, Guillaume Beslon (2024) Emergence of Supercoiling-Mediated Regulatory Networks through the Evolution of Bacterial Chromosome Organization. bioRxiv, ver. 4 peer-reviewed and recommended by Peer Community in Mathematical and Computational Biology https://doi.org/10.1101/2022.09.23.509185 | Emergence of Supercoiling-Mediated Regulatory Networks through the Evolution of Bacterial Chromosome Organization | Théotime Grohens, Sam Meyer, Guillaume Beslon | <p>DNA supercoiling -- the level of twisting and writhing of the DNA molecule around itself -- plays a major role in the regulation of gene expression in bacteria by modulating promoter activity. The level of DNA supercoiling is a dynamic property... | | Biophysics, Evolutionary Biology, Systems biology | Nelle Varoquaux | 2023-06-30 10:34:28 |




